🇧🇷 Projetando e escalando um sistema para 100 milhões de usuários diários (Bit.ly)
March 22, 2025
*This post is in Portuguese, as I want to contribute to the Brazilian community that studies system design. Para quem está se preparando para entrevistas de System Design um dos cases mais clássicos é "Como projetar e escalar um encurtador de URLs (Como o bit.ly)", ela testa sua capacidade de pensar em escalabilidade, consistência, particionamento de dados, e decisões arquiteturais sob pressão.
Neste post, vamos discutir algumas abordagens possíveis para esse problema e mostrar como você pode estruturar seu raciocínio para ir bem em entrevistas — mas também para crescer como engenheiro de software.
Requisitos funcionais e não funcionais
A primeira coisa que você deve pensar é nos requisitos funcionais e não funcionais do seu sistema. Requisitos funcionais são as features que o sistema deve ter para sanar a dor do seu usuário, o que seu sistema faz que entrega valor? No caso do bit.ly podemos pensar em alguns requisitos funcionais importantes:
Os usuários precisam conseguir enviar uma URL e receber uma versão mais curta.
Os usuários precisam conseguir acessar a URL original através da versão encurtada.
E os requisitos não funcionais? No geral, eles são especificações de como o sistema deve operar, alguns exemplos de requisitos não funcionais pro nosso caso de estudo são:
O sistema deve garantir que cada URL encurtada seja única (Uma URL encurtada não pode apontar para duas URLs normais).
O redirect deve ser feito de forma rápida (de preferência menor do que 100ms).
O sistema deve estar disponível 99.9% do tempo.
O sistema deve conseguir escalar para 100M DAU (Usuários ativos por dia) e suportar 1 bilhão de URLs encurtadas.
Podemos perceber que nosso sistema terá uma grande discrepância entre operações de leitura e escrita (afinal, muito mais pessoas tentarão acessar um site via uma URL encurtada do que pessoas tentarão encurtar URLs). Isso é importante e afeta muito a estratégia.
Pense nas suas entidades
Em um primeiro momento, antes de começar a desenhar precisamos pensar nas entidades core do nosso banco de dados. Neste caso podemos imaginar que para o sistema precisaremos de uma tabela chamada de "ShortenedURL" simples, com:
URL Original
URL encurtada
User
API
Como todo sistema, precisamos de rotas para definir as comunicações, em uma entrevista de system design é interessante especificar essas rotas. Que rotas você imaginaria que esse sistema teria?
POST /url
GET /{short_url}
De forma simples, conseguimos atender nossos dois requisitos funcionais. Uma rota serve para criar a URL encurtada e outra rota serve para buscar uma URL original.
Desenho
Após definir seus requisitos, suas entidades principais e sua api, tudo está pronto para começar o desenho do sistema. Nesta etapa é interessante definir tudo da forma mais simples possível, deixando as complexidades para quando forem surgindo. (diga não ao over-engineering)
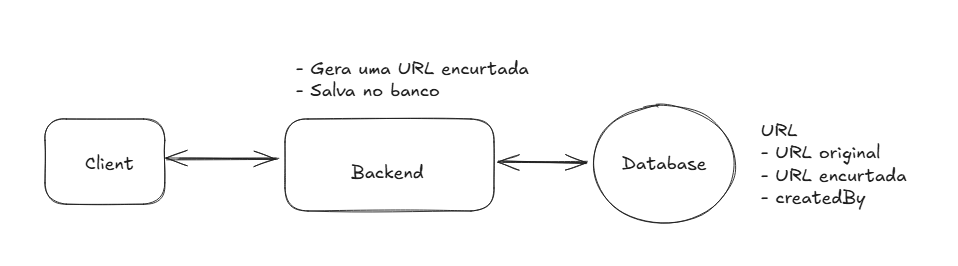
High Level Design POST
O usuário manda uma URL para ser encurtada através do client (frontend), o server recebe essa request e verifica se ela é válida (existe uma infinidade de libs que estão disponíveis por aí que fazem isso) e se ela já não existe no sistema, então encurta a URL e salva no banco e retorna a URL curta. Vamos deixar a ação de salvar no banco de forma simples por agora.
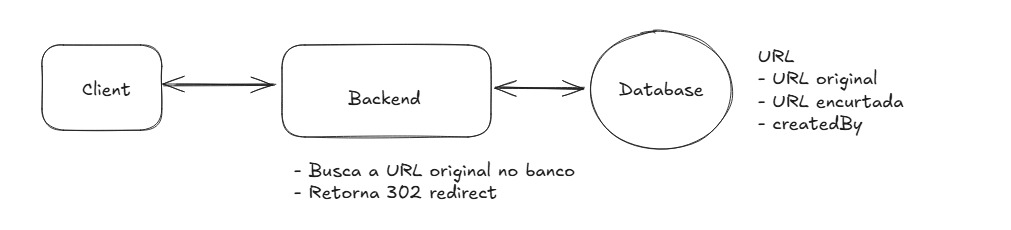
High Level Design GET
Já para o GET, o fluxo começa com o usuário mandando um requisição do client, que é recebida pelo server primário e busca no banco de dados pela URL curta (ex: abc123), caso ela seja encontrada o server retorna uma resposta de redirect, instruindo o browser a navegar para a URL original. Existem dois tipos de redirect:
301 (Redirect permanente): O recurso foi movido permanentemente para a URL de destino. Esse tipo de redirect é cacheado pelo browser, isso significa que requests subsequentes para essa mesma URL encurtada podem ir direto para a URL original, um problema para nosso caso de uso.
302 (Redirect temporário): O recurso foi movido temporariamente para a URL de destino. Não é cacheada, isso quer dizer que futuras requests a essa URL encurtada passarão pelo nosso server primeiro, dessa forma sempre haverá uma consulta e o usuário sempre será redirecionado para o destino correto.
Aprofundando
Em uma entrevista é esperado que após dar a solução inicial, como acabamos de fazer, você se aprofunde em alguns problemas previstos do design.
Como nós garantimos que as URLs curtas sejam únicas?
A primeira questão que pode vir e que você deve estar se perguntando é: Como nós garantimos que as URLs curtas sejam únicas? Ou seja, como nós garantimos que uma URL encurtada não seja gerada mais de uma vez.
A resposta pode variar muito dependendo de como você pensa e resolve problemas, mas no geral, existe uma solução "padrão": Encodar a URL em base62 com referência a um contador único.
Primeiro, por quê Base62?
Base62 é um método de codificação que representa números em uma base com 62 caracteres ( (26) + (26) + (10) = 62), enquanto o Base64 encoda nesses mesmos caratecteres MAIS "+" e "/". Nós não precisamos desses caracteres especiais para encurtar nossas URLs.
Se quisermos saber quantas combinações diferentes podemos gerar com caracteres em Base62, usamos 62^n. Se usarmos 6 caracteres = 62^6 = 56 bilhões.
Ou seja, com apenas 6 caracteres conseguimos representar 56 bilhões de combinações únicas. Muito mais do que precisamos para nosso requisito não funcional de 1 bilhão de URLs encurtadas.
Na prática para gerar essas URLs únicas uma abordagem comum é usar um contador incremental. A cada nova URL gerada, incrementamos o contador em += 1, em seguida transformamos esse número inteiro em Base62, o que nos dá a URL encurtada. Essa técnica é eficiente, simples e segura pois garante o risco de colisões (quando uma mesma URL curta aponta para mais de uma URL original), desde que o contador seja controlado corretamente.
Por isso, como contador podemos usar uma instância do Redis, por suportar instruções atômicas o Redis se torna ideal para nosso caso de uso. Mesmo com múltiplas instâncias de serviço aumentando a contagem ele garante que a operação de increment do contador seja única.
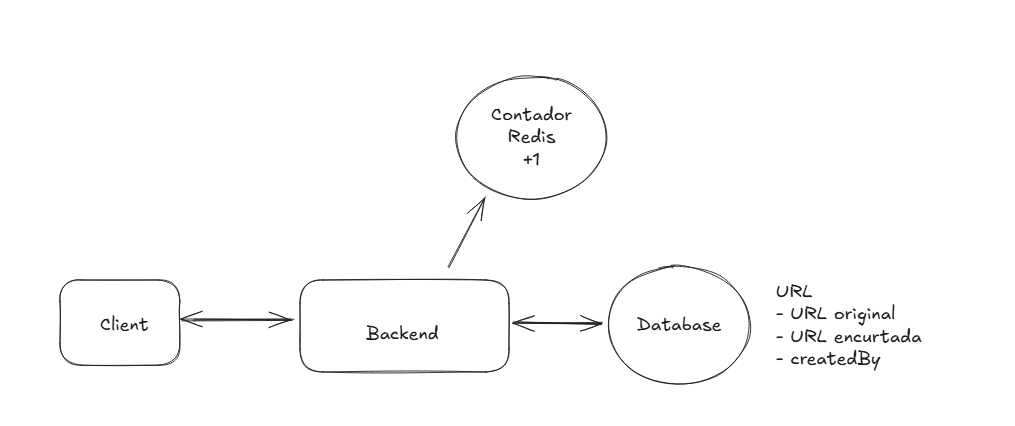
High Level Design com Redis
Como podemos garantir que os redirects sejam rápidos?
Para garantir isso uma boa abordagem seria introduzir um cache in-memory entre o serviço e o banco de dados, antes de checar no banco, nosso sistema verifica se a URL está no cache, isso por que a memória cache é muito mais rápida que um fetch no banco de dados:
Tempo de acesso em memória: 100 nanosegundos (0.0001 ms)
Tempo de acesso no HD: 10 milisegundos
Acessar um dado na memória é 100 mil vezes mais rápido do que acessar um dado no HD.
Exemplos de cache são: Redis e Memcached.
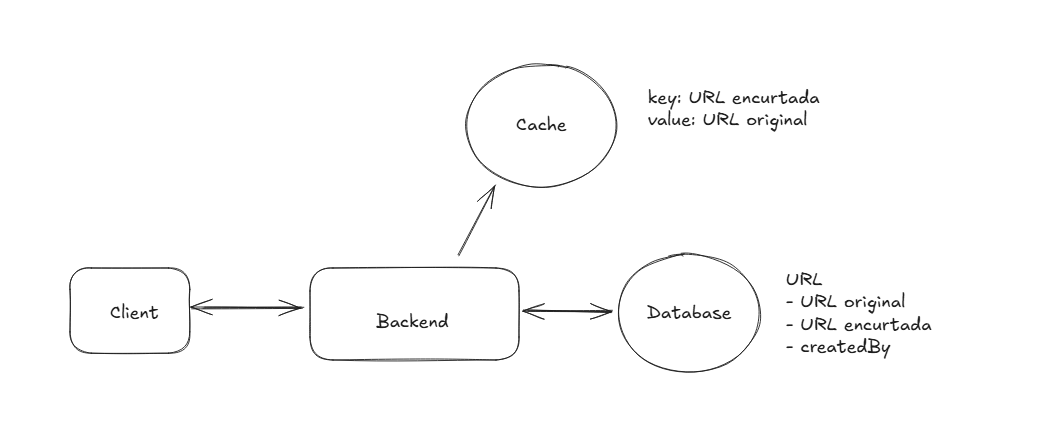
High Level Design Cache
Antes de verificar no banco, verificamos no Cache se a URL encurtada está disponível. Caso esteja, retornamos rapidamente. Caso não esteja, buscamos no banco e salvamos no cache para consultas futuras.
Como podemos escalar para 1B de URLs curtas e 100M usuários ativos diários?
No nosso caso, cada linha no banco de dados armazena: a URL original (~100 bytes), a URL encurtada (ou o código curto, ~8 bytes) e o ID do usuário que criou (~8 bytes). Isso dá aproximadamente 116 bytes por registro.
Mas por que o código curto ocupa apenas ~8 bytes?
Porque usamos uma string curta em Base62 com 6 caracteres, lembra? cada caractere em uma string geralmente ocupa 1 byte (em UTF-8, no caso de caracteres simples como letras e números). Logo, um código com até 8 caracteres em Base62 ocupa aproximadamente 8 bytes. (em system design temos a mania de arredondar tudo para múltiplos de base10).
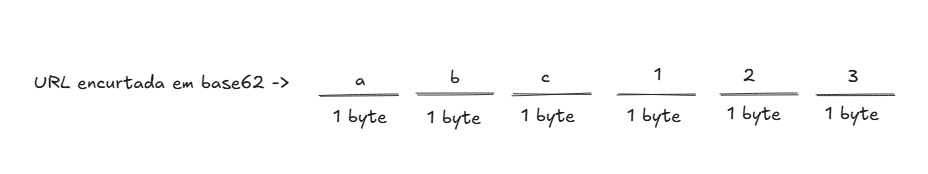
Cálculo do tamanho da URL encurtada
Voltando, se arredondarmos os 116 bytes por registros para 200 bytes e multiplicarmos por 1 bilhão de URLs, teremos cerca de 200GB de dados.
Esse volume é tranquilamente suportado por SSDs modernos, e pode ser distribuído em shards ou clusters de banco de dados, caso necessário. Ou seja, do ponto de vista de armazenamento, não é um gargalo para esse tipo de sistema.
Como escalar nosso server primário (backend)?
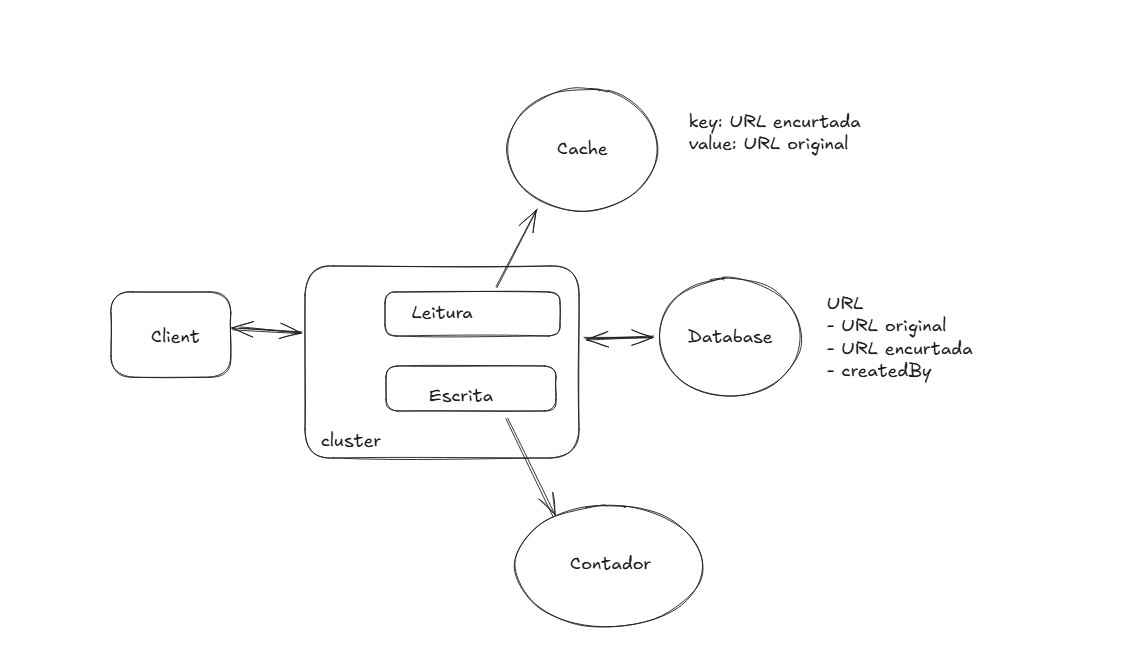
Para este problema nós podemos simplesmente ir para o clássico - Micro-serviços! Separamos em instâncias destinadas a leitura e escrita (pois nosso sistema exige muito mais leituras do que escritas), assim podemos escalar horizontalmente em um cluster conforme a necessidade.
High Level Design Cluster
Mas e como escalamos nosso contador?
Bom, como nosso contador precisa ser uma fonte única de verdade, isso é, todos nossos micro-serviços de escrita irão consultar ele, ele não pode falhar. Como faremos isso?
Uma alternativa é "counter batching" .
Cada serviço de escrita pode requisitar 1000 números do contador.
A instância do contador incrementa esses 1000 números e devolve o batch para o micro-serviço.
O serviço de escrita então segue usando esses 1000 números localmente para encurtar as URLs, até que eles acabem e ele requisite uma nova batch.
Dessa forma, mantemos nosso contador com baixo overhead e alta disponibilidade, evitando chamadas constantes ao serviço centralizado e reduzindo o risco de gargalos ou falhas.
Conclusão
É claro que esse post não cobre todos os detalhes possíveis de um sistema como o Bit.ly. Existem muitas outras decisões importantes a se discutir: segurança, analytics, custom aliases, sistemas distribuídos com alta tolerância a falhas, e muito mais.
Meu objetivo aqui foi mostrar um caminho claro de raciocínio para quem está se preparando, assim como eu, para entrevistas de System Design.
Se você quiser se aprofundar mais nesse tema, recomendo fortemente o blog Hello Interview do Evan King, que foi uma grande referência na criação deste post.
Se esse conteúdo te ajudou, compartilhe com alguém que também esteja estudando e deixe um comentário com o que você gostaria de ver nos próximos posts!
DISCUSSION.LOG
No comments yet. Be the first to comment!
ADD_COMMENT
© 2025 BITWISEOPS BLOG - All rights reserved